Mercury 2: el modelo de difusión que redefine la velocidad de la IA
Mercury 2 de Inception Labs genera 1009 tokens por segundo con 1.7s de latencia. Analizo la arquitectura de difusión, benchmarks reales y por qué este es el futuro de todos los LLMs.

Índice de contenido
Mercury 2 se lanzó el 24 de febrero de 2026 y el número que aparece primero en cualquier análisis es ese: 1,009 tokens por segundo. No es un benchmark de laboratorio aislado. Es latencia real end-to-end de 1.7 segundos para una tarea completa. Para ponerlo en contexto: Claude 4.5 Haiku genera 89 tokens por segundo. GPT-5 Mini, 71. La misma tarea que a Haiku le toma 23 segundos, Mercury 2 la resuelve en 1.7.
La pregunta que me hice al ver esos números no fue “¿es real?”, sino “¿por qué los modelos que usamos todos los días no funcionan así?”. La respuesta tiene que ver con una decisión arquitectónica que se tomó hace años y que la industria ha estado arrastrando desde entonces. Mercury 2 demuestra que hay otra forma.
Mercury 2 no es solo el modelo más rápido del mercado. Es la evidencia de que la arquitectura de difusión puede competir en calidad con los mejores modelos speed-optimized mientras elimina el cuello de botella más fundamental que tienen los LLMs actuales.
¿Qué es Mercury 2?
Mercury 2 es el primer modelo de razonamiento de uso general basado en arquitectura de difusión (Diffusion Language Model, DLM). Lo desarrolló Inception Labs, una startup fundada en 2024 en Palo Alto, California, por investigadores de Stanford, UCLA y Cornell que llevan años estudiando cómo aplicar los principios de difusión — los mismos que usan Stable Diffusion o DALL-E para generar imágenes — al lenguaje.
Lo que lo diferencia de cualquier otro modelo que hayas visto no es el número de parámetros ni el tamaño del dataset de entrenamiento. Es la arquitectura: Mercury 2 no genera texto token a token. Genera bloques completos en paralelo y los refina iterativamente, como si tomara un borrador y lo fuera mejorando, en lugar de escribir cada palabra esperando a la anterior.
El resultado práctico: genera un artículo de 2,000 palabras en aproximadamente 2.5 segundos. Un modelo autoregresivo estándar tarda entre 20 y 30 segundos en la misma tarea.
Resumen en 90 segundos
- Lanzamiento: 24 de febrero de 2026.
- Empresa: Inception Labs (Palo Alto, fundada 2024).
- Arquitectura: Diffusion Language Model (DLM).
- Velocidad: 1,009 tokens/seg en GPU NVIDIA Blackwell.
- Latencia E2E: 1.7 segundos.
- Precio: $0.25 input / $0.75 output por millón de tokens.
- Contexto: 128K tokens.
- Compatible con API OpenAI: Sí — integrable sin reescribir código.
- JSON schema-aligned: Sí.
- Benchmarks destacados: AIME 91, GPQA Diamond 74, IFBench 71.
- Más rápido que: Claude 4.5 Haiku (89 tokens/seg), GPT-5 Mini (71 tokens/seg).
La revolución silenciosa: qué es un modelo de difusión
Para entender por qué Mercury 2 importa, hay que entender primero por qué los modelos que usamos hoy son tan lentos en relación a lo que podrían ser.
Los modelos de lenguaje actuales — GPT, Claude, Gemini — son autoregresivos. Eso significa que generan el texto de izquierda a derecha, un token a la vez. Para generar el token 500, el modelo tiene que haber generado los 499 anteriores. Es una dependencia secuencial que hace imposible la paralelización real durante la generación.
Hay un nombre técnico para el problema que esto crea: el cuello de botella del caché KV (Key-Value cache). Cada token generado requiere que el modelo almacene y acceda a representaciones de todos los tokens anteriores. A medida que la secuencia crece, ese proceso se vuelve progresivamente más costoso en memoria y compute. Es inherente a la arquitectura, no algo que se resuelva con hardware más rápido.
Los modelos de difusión para texto funcionan de manera fundamentalmente diferente:
- Comienzan con ruido: en lugar de empezar de izquierda a derecha, toman la respuesta objetivo representada como una secuencia “ruidosa” (similar a una imagen borrosa).
- Refinan iterativamente en paralelo: en cada paso de “denoising”, el modelo modifica y mejora múltiples tokens simultáneamente.
- Convergen en la respuesta: después de varios pasos de refinamiento, el texto ruidoso se convierte en texto coherente y de alta calidad.
La analogía más clara es la que ya conocés de Stable Diffusion o Midjourney: no generan una imagen píxel a píxel de arriba a abajo, sino que parten de ruido y lo van refinando hasta que emerge la imagen. Mercury 2 hace lo mismo con el texto.
Esto elimina la dependencia secuencial. El modelo puede procesar la secuencia completa en paralelo en cada paso de refinamiento, generando mucho más trabajo útil por evaluación de la red neuronal.
No es una idea nueva en imágenes, pero aplicarla al lenguaje con calidad comercial es lo que Inception Labs demostraron con Mercury 2.
Por qué Mercury 2 es 5 veces más rápido: la explicación técnica
Los 1,009 tokens por segundo no vienen de hardware especial exclusivo ni de atajos en la calidad. Vienen de la arquitectura.
Cuando un modelo autoregresivo genera 512 tokens, hace 512 pasadas hacia adelante por la red. Cada pasada depende del resultado de la anterior. No hay forma de hacer esas 512 pasadas en paralelo porque cada una requiere el output de la pasada previa.
Mercury 2 hace el mismo trabajo en un número mucho menor de pasos. Cada paso de refinamiento procesa toda la secuencia en paralelo, modificando múltiples tokens simultáneamente. El costo por token es diferente, pero el throughput real — la cantidad de texto generado por segundo — es drásticamente mayor.
Hay tres factores técnicos que contribuyen a la ventaja de velocidad:
1. Eliminación de la dependencia causal Los modelos autoregresivos tienen una máscara causal que impide que cada token “vea” los tokens futuros durante la generación. Los modelos de difusión no tienen esa restricción: cada paso de refinamiento puede usar contexto bidireccional, lo que hace que cada evaluación de la red sea más informativa.
2. Compute más eficiente por token generado En autoregresivo, cada paso de generación produce exactamente un token. En difusión, cada paso refina todos los tokens a la vez. La razón “tokens producidos / evaluaciones de red” es órdenes de magnitud mayor en difusión.
3. Sin caché KV creciente El caché KV de los modelos autoregresivos crece con la longitud de la secuencia. En Mercury 2, el proceso de refinamiento no acumula estado de esa manera, lo que reduce el footprint de memoria y permite mayor paralelismo en GPU.
El resultado: Mercury 2 genera textos completos en el tiempo que un modelo autoregresivo tarda en generar los primeros tokens.
Benchmarks: los números que importan
Velocidad es una cosa. La pregunta es si Mercury 2 sacrifica calidad para lograrla. Los benchmarks dan una respuesta matizada.
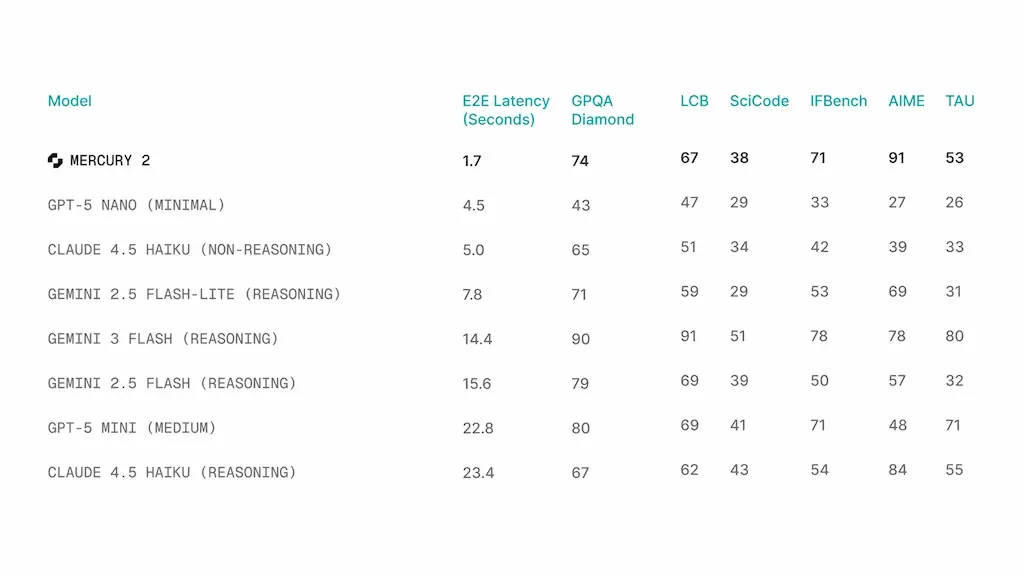
Comparativa completa de rendimiento y velocidad
| Modelo | Latencia E2E (seg) | GPQA Diamond | LCB | SciCode | IFBench | AIME | TAU |
|---|---|---|---|---|---|---|---|
| Mercury 2 | 1.7 | 74 | 67 | 38 | 71 | 91 | 53 |
| GPT-5 Nano (Minimal) | 4.5 | 43 | 47 | 29 | 33 | 27 | 26 |
| Claude 4.5 Haiku (No-Reasoning) | 5.0 | 65 | 51 | 34 | 42 | 39 | 33 |
| Gemini 2.5 Flash-Lite (Reasoning) | 7.8 | 71 | 59 | 29 | 53 | 69 | 31 |
| Gemini 3 Flash (Reasoning) | 14.4 | 90 | 91 | 51 | 78 | 78 | 80 |
| Gemini 2.5 Flash (Reasoning) | 15.6 | 79 | 69 | 39 | 50 | 57 | 32 |
| GPT-5 Mini (Medium) | 22.8 | 80 | 69 | 41 | 71 | 48 | 71 |
| Claude 4.5 Haiku (Reasoning) | 23.4 | 67 | 62 | 43 | 54 | 84 | 55 |
Fuente: Inception Labs, benchmark publicado el 24 de febrero de 2026.
Lo que me llama la atención al analizar estos números:
Mercury 2 no es el modelo más inteligente en calidad absoluta. Gemini 3 Flash (Reasoning) lidera en casi todas las métricas de calidad cuando le das 14 segundos. GPT-5 Mini y Claude 4.5 Haiku Reasoning también superan a Mercury 2 en varias categorías cuando se les permite usar razonamiento.
Pero Mercury 2 hace algo que ninguno de esos modelos puede hacer: obtener esos scores en 1.7 segundos. La relación calidad/velocidad es una categoría diferente.
Hay un número que me parece particularmente notable: AIME 91. El American Invitational Mathematics Examination es uno de los benchmarks más exigentes en razonamiento matemático. Que Mercury 2 obtenga 91 — el score más alto de toda la tabla — con la arquitectura de difusión y en 1.7 segundos de latencia, sugiere que el refinamiento iterativo tiene propiedades interesantes para el razonamiento matemático que todavía no están completamente exploradas.
Benchmark de velocidad

| Modelo | Tokens por segundo |
|---|---|
| Mercury 2 | 1,009 |
| Claude 4.5 Haiku | 89 |
| GPT-5 Mini | 71 |
La diferencia no es incremental. Es más de 11x sobre Claude Haiku y 14x sobre GPT-5 Mini. En términos prácticos: mientras Mercury 2 genera 1,000 tokens, Haiku está en los primeros 89.
Qué significan estos números en uso real
Para la mayoría de los casos de uso donde la velocidad importa — agentes de código, asistentes de voz, sistemas de soporte en tiempo real — Mercury 2 no es “un poco más rápido”. Es un orden de magnitud diferente.
Un pipeline de generación de contenido que hoy procesa 10 artículos por minuto con Claude Haiku procesaría 113 con Mercury 2, al mismo costo o menor, dado el precio de $0.25/$0.75 por MTok.
Hay que ser honesto sobre lo que Mercury 2 no es: si necesitás el mejor razonamiento posible sin restricción de tiempo, Gemini 3 Flash Reasoning o Claude 4.5 Haiku Reasoning ofrecen scores más altos. La elección entre modelos siempre depende del caso de uso específico.
Inception Labs: los pioneros de la difusión
Inception Labs no es una startup que pivotó hacia difusión porque era el tema del momento. La empresa se fundó específicamente para resolver el problema de los modelos de difusión para lenguaje a escala comercial.
Equipo fundador:
- Stefano Ermon — Profesor de Stanford y uno de los investigadores que estableció los fundamentos teóricos de los modelos de difusión.
- Aditya Grover — Profesor de UCLA, investigador de score-based generative models.
- Volodymyr Kuleshov — Profesor de Cornell, trabajo en aplicaciones de difusión a datos estructurados.
No es accidental que los tres sean académicos especialistas en difusión, no generalistas de deep learning que se subieron a una tendencia.
Financiamiento:
- Ronda seed de $50 millones en noviembre de 2025, liderada por Menlo Ventures.
- Participaron: Mayfield, M12 (Microsoft), Snowflake Ventures, Databricks Ventures.
- Inversores ángeles: Andrej Karpathy (co-fundador de Tesla AI, ex OpenAI) y Andrew Ng (co-fundador de Coursera, Google Brain).
El hecho de que Karpathy y Ng estén invertidos no es solo un respaldo de reputación. Ambos han hablado públicamente sobre el potencial de difusión como cambio arquitectónico real para el lenguaje.
Trayectoria: Antes de Mercury 2, Inception Labs lanzó Mercury Coder — un modelo de difusión especializado en código que demostró la viabilidad técnica del enfoque en tareas reales. Mercury Coder Mini alcanzó 1,109 tokens por segundo en H100; Mercury Coder Small, 737 tokens por segundo. Los resultados de Mercury Coder les dieron la evidencia interna de que la arquitectura podía escalar a razonamiento general.
Mercury 2 es la versión de uso general: razonamiento, instrucciones, conocimiento, código — todo lo que esperarías de un modelo tier-1.
El futuro de los modelos de difusión
Mercury 2 no es un caso aislado. Es la convergencia de varios desarrollos que llevaban tiempo construyéndose en paralelo.
En mayo de 2025, Google DeepMind presentó Gemini Diffusion en Google I/O. Un modelo de difusión basado en la arquitectura Gemini que alcanzó 1,479 tokens por segundo — incluso más rápido que Mercury 2 — manteniendo paridad de rendimiento con modelos autoregresivos comparables.
Que Google, con todos los recursos para optimizar modelos autoregresivos al máximo, eligiera invertir en difusión dice algo sobre hacia dónde va la investigación.
¿Qué viene después?
Multimodalidad nativa: Los modelos de difusión tienen una ventaja estructural para la generación multimodal. La misma arquitectura que refina tokens de texto puede refinar representaciones de imagen, audio o video en paralelo. El trabajo de VideoLLaMA 2 y SyncFlow ya mostró que difusión puede sincronizar múltiples modalidades de manera más natural que los enfoques autoregresivos.
Control fino sobre las salidas: La arquitectura de difusión permite modificar el proceso de generación con restricciones duras. En lugar de “guiar” al modelo con prompting, podés intervenir directamente en los pasos de refinamiento para garantizar propiedades específicas de la salida — sin violaciones. Esto es relevante para aplicaciones de seguridad, generación de código con restricciones formales o diseño molecular.
Eficiencia de datos mejorada: Investigación reciente de Carnegie Mellon (septiembre 2025) demostró que los modelos de difusión masked superan a los modelos autoregresivos en regímenes de datos limitados. A medida que los datasets de preentrenamiento se vuelven más escasos o costosos, la difusión tiene ventaja.
Leyes de scaling propias: Los modelos de difusión siguen curvas de scaling diferentes a los autoregresivos. Todavía no entendemos completamente esas curvas, pero la evidencia sugiere que hay espacio para mejoras sustanciales con el mismo compute que hoy produce modelos autoregresivos tier-2.
Los desafíos que quedan — mayor complejidad de entrenamiento, mayor compute requerido para igualar el log-likelihood de autoregresivos en benchmarks específicos — son problemas de ingeniería. No barreras fundamentales. Son el tipo de problemas que se resuelven con más investigación, más recursos y más iteraciones. No requieren descubrir nueva física.
Por qué todos los modelos deberían adoptar la difusión
Voy a ser directo sobre mi opinión: la generación token-a-token es un cuello de botella que la industria debería estar trabajando activamente para abandonar, y Mercury 2 es la demostración de que ya es posible hacerlo.
No digo esto porque difusión sea la única arquitectura posible. Digo esto porque la restricción de generar texto de izquierda a derecha, un token a la vez, no tiene fundamento en cómo funciona el pensamiento o la comunicación — es un artefacto de cómo se entrena a los modelos para predecir el siguiente token.
La velocidad que Mercury 2 logra no es solo “más rápido para el usuario”. Habilita categorías de productos que hoy no existen:
Asistentes de voz verdaderamente conversacionales: Con latencia de 1.7 segundos, la diferencia entre “hablo con una IA” y “hablo con alguien” se vuelve perceptualmente pequeña. Los asistentes de voz actuales tienen latencias de 3-8 segundos que hacen la conversación antinatural. Mercury 2 cambia ese límite.
Agentes de código que no te hacen esperar: Autocomplete de código en tiempo real, refactoring inline, generación de tests mientras escribís. Hoy esperamos segundos por cada sugerencia. Con Mercury 2, esa espera desaparece.
Pipelines de procesamiento masivo económicos: $0.75 por millón de tokens de salida a 1,009 tokens/segundo hace viable procesar volúmenes que antes eran prohibitivos en costo o tiempo.
La analogía que me parece más precisa es el salto de discos duros mecánicos a SSDs. Los discos duros seguían funcionando, tenían años de optimización acumulada, y para muchos casos de uso la diferencia no era perceptible. Pero había una razón estructural por la que el SSD era superior, y una vez que el costo bajó lo suficiente, no había razón para volver. Los autoregresivos van a seguir siendo relevantes por años — hay demasiada infraestructura construida alrededor de ellos. Pero la dirección del cambio ya es visible.
El contraargumento honesto: Difusión todavía no es la mejor arquitectura para todo. En tareas de razonamiento complejo de alta complejidad sin restricción de tiempo, los modelos autoregresivos con cadenas de pensamiento largas siguen siendo superiores. Gemini 3 Flash Reasoning obteniendo 90 en GPQA Diamond vs 74 de Mercury 2 es un gap real. Pero ese gap se va a cerrar. La investigación en “reasoning diffusion” — combinar el proceso de refinamiento iterativo con razonamiento explícito — está apenas empezando.
Mi lectura: los laboratorios que hoy tienen modelos de difusión como investigación secundaria van a tener que decidir en los próximos 18-24 meses si lo convierten en su arquitectura principal. Mercury 2 y Gemini Diffusion juntos son evidencia suficiente de que el enfoque es viable a escala comercial.
Casos de uso ideales para Mercury 2
Basándome en los benchmarks y la arquitectura, estos son los casos donde Mercury 2 tiene ventaja real:
1. Asistentes de voz en tiempo real
La latencia de 1.7 segundos es el diferenciador más claro. Para sistemas donde el usuario espera una respuesta hablada, cada segundo de latencia perceptible rompe la ilusión de conversación natural. Mercury 2 comprime ese tiempo al mínimo técnicamente alcanzable hoy.
2. Autocomplete de código en IDEs
La diferencia entre 89 tokens/seg (Haiku) y 1,009 tokens/seg (Mercury 2) se traduce en sugerencias de código que aparecen antes de que el usuario haya terminado de tipear el contexto. Para herramientas como Cursor, Copilot o Windsurf, la velocidad de generación es un factor de experiencia de usuario directo.
3. Triage de soporte al cliente
Sistemas que clasifican, resumen y priorizan tickets de soporte procesan múltiples entradas en paralelo. Con Mercury 2, un pipeline que hoy tarda 30 segundos por ticket puede reducir eso a 2-3 segundos, habilitando respuesta en tiempo real en lugar de procesamiento en batch.
4. Pipelines de contenido a escala
Generación de descripciones de productos, resúmenes de documentos, traducciones de primer borrador. Tareas donde la calidad necesaria es “buena, no perfecta” y el volumen importa. El costo de $0.75/MTok de salida a 1,009 tokens/seg hace que estos pipelines sean económicamente viables a escalas que antes requerían optimización agresiva de costos.
5. Agentes de IA conversacionales
Los agentes que tienen que mantener conversación natural, responder preguntas en contexto y hacer múltiples llamadas a herramientas se benefician directamente de la reducción de latencia acumulada. Cada llamada al modelo que se reduce de 5 segundos a 1.7 segundos cambia la experiencia del usuario de “esperando al agente” a “trabajando con el agente”.
Cuándo NO usar Mercury 2
Si el caso de uso requiere el máximo razonamiento posible sin restricción de tiempo — análisis científico profundo, resolución de problemas matemáticos de alta complejidad, coding agentico de largo alcance con múltiples herramientas — los modelos con cadenas de pensamiento largas como Gemini 3 Flash Reasoning o Claude 4.5 Haiku Reasoning siguen siendo superiores en calidad absoluta. Mercury 2 no pretende competir en ese espacio todavía.
Mis conclusiones
Mercury 2 es el tipo de lanzamiento que importa no por lo que hace hoy sino por lo que demuestra que es posible.
Lo que hace hoy: un modelo competitivo en calidad con los mejores modelos speed-optimized del mercado, que es 5 veces más rápido que todos ellos y más económico. Para los casos de uso donde la velocidad es el factor crítico, ya no hay razón para usar otra cosa.
Lo que demuestra: que la arquitectura de difusión puede llevar razonamiento real a latencias que los autoregresivos no pueden alcanzar estructuralmente. Que Inception Labs — con $50 millones de seed y un equipo de tres profesores — puede construir algo que obliga a Google DeepMind, Anthropic y OpenAI a replantear sus hojas de ruta de arquitectura.
Lo que predigo: en los próximos 24 meses vamos a ver al menos dos de los tres grandes laboratorios (Google, OpenAI, Anthropic) anunciar modelos basados en difusión como parte de su línea principal, no como investigación experimental. Google ya lo confirmó con Gemini Diffusion. El resto va a seguir porque la física del problema no cambia: generar texto token a token es intrínsecamente serial, y serial es intrínsecamente lento comparado con paralelo.
Para los developers que leen esto: el momento de experimentar con Mercury 2 es ahora, mientras la competencia todavía está evaluando si la difusión es “real”. Los que entiendan las ventajas y limitaciones hoy van a estar mejor posicionados cuando la arquitectura sea mainstream.
La API está disponible, es compatible con OpenAI, y el precio es menor que el de los modelos que ya usás. El único costo es el tiempo de evaluar si tu caso de uso se beneficia de 1.7 segundos de latencia. Para la mayoría de los casos donde hoy esperás 5 segundos o más, la respuesta va a ser que sí.
Fuentes
- Inception Labs — Introducing Mercury 2
- BusinessWire — Inception Launches Mercury 2
- The Decoder — Inception launches Mercury 2: the first diffusion-based language reasoning model
- TechCrunch — Inception raises $50 million to build diffusion models for code and text
- eWeek — Mercury 2 Is 13x Faster Than Claude Haiku
- The Neuron Daily — Mercury 2: AI that’s 10x faster than ChatGPT & Claude
- Analytics Vidhya — Mercury 2: The AI Model That Feels Instant
- Carnegie Mellon ML Blog — Diffusion Beats Autoregressive in Data-Constrained Settings
- IBM Think — Diffusion models challenge GPT as next-generation AI emerges
- Artificial Analysis — Mercury 2 Intelligence, Performance & Price Analysis